
So once upon a time I had a landing page. Nothing fancy, just my page. I made it look pretty, since It was intended to be the focal point of all my activities, my Lofi Study material, my GitHub learning repo, Custom K8s GPT Instance, and my proper GitHub Repo. But I wanted to chronicle my journey too. That’s when I opened Wordpress account. But that made me feel dirty, as surely I could deploy that myself. How could I talk about loving open source and being an a DIY pro if I am using such a heavily managed element in my setup? So that portion only lasted for 3 weeks. As not disrupt the flow of the landing page (I got really good at git rollbacks), I decided to deploy Ghost, which I found to be more lightweight than Wordpress, on a separate VM on AWS through Docker, using the official image.
I connected this to the static page as a backend by reverse proxying it through Nginx. It was a bit complicated and was prone to errors, as depending on seemingly random occasions, Nginx would fail to serve the CSS and JS assets from Ghost.
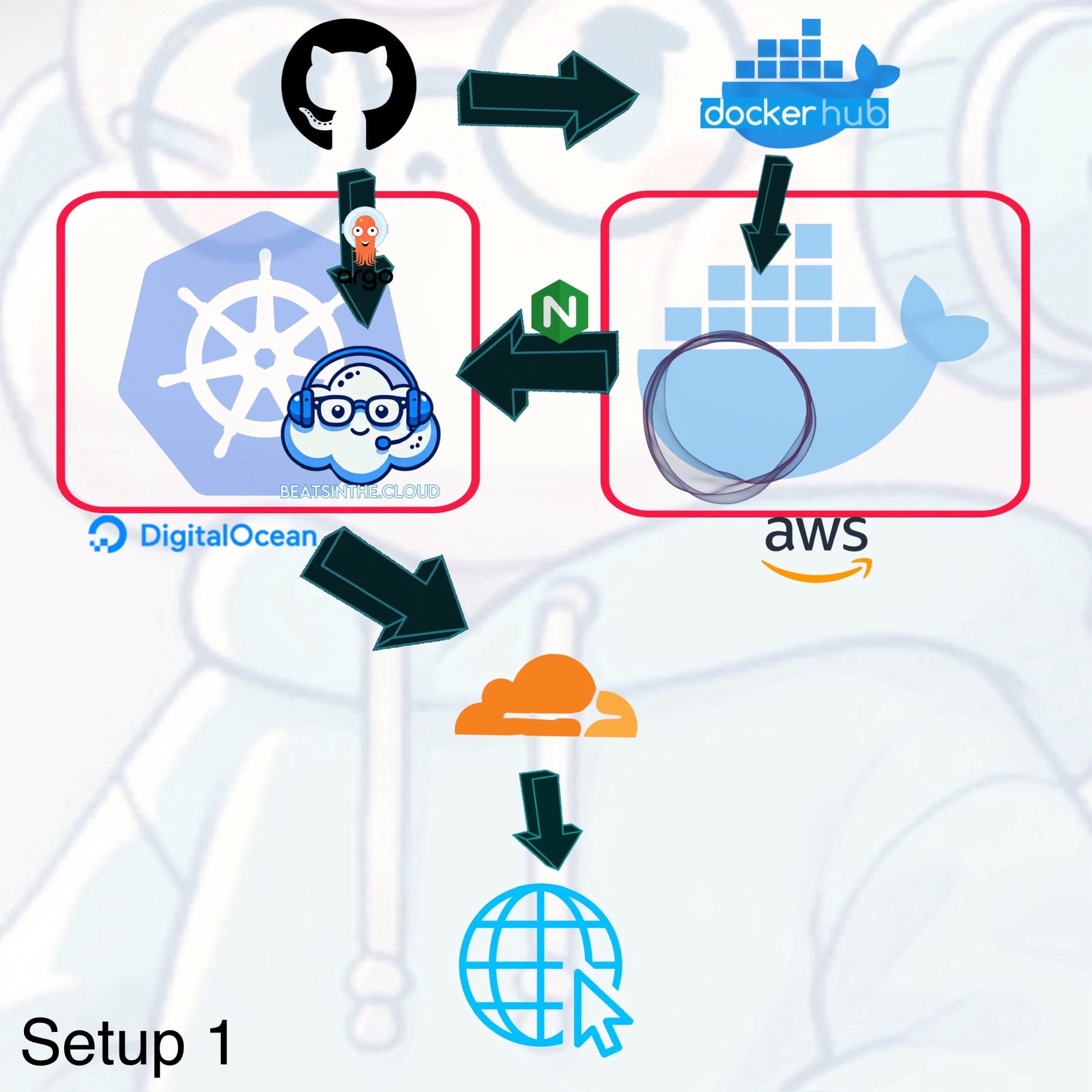
The initial setup utilized DigitalOcean’s managed Kubernetes, which I enjoyed for its ease of use, while also incorporating the aforementioned AWS. For observability, Prometheus and Grafana were used to monitor the cluster’s health, while K9s provided a simplified, terminal-based interface for managing Kubernetes. The deployment pipeline followed a GitOps approach with GitHub and ArgoCD, automating deployments from source code repositories, and Cloudflare was used for DNS management and secure SSL/TLS encryption and Proxying. DigitalOcean made the cluster setup easy to maintain, allowing me to focus on deployments rather than infrastructure maintenance. The multi-cloud approach leveraged the strengths of different cloud providers, but as I mentioned before managing multiple environments introduced complexity in terms of traffic management, networking, and eventual cost increase (once credits ran out on both providers). The unnecessary complexity of managing multiple cloud environments was painfully obvious. It was challenging to maintain consistent configurations and networking across both DigitalOcean and AWS. Consolidating the infrastructure to a single provider would reduce this complexity, streamline management, and optimize costs. Listen dude, I want to keep this project under $20 a month.
The migration phase involved moving the Kubernetes cluster to a self-hosted K3s setup on Hetzner, consolidating all workloads under a single cloud provider. This change was aimed at reducing complexity and improving cost efficiency. To make up for the lack of native UI Digital Ocean offered, I implemented Prometheus, Grafana and K9s for monitoring and managing the K3s cluster. The pricing of Hetzner's VPSs more than made up for this, as I was able to get a workhorse of a virtual machine for a really good price even with with the additional fees for snapshots and backups. Through a GitOps approach, migration was relatively painless and fast. It took about an hour to install K3s, Argo, the observability tools and redeploy the site and reconfigure DNS. Literally nearly zero downtime.
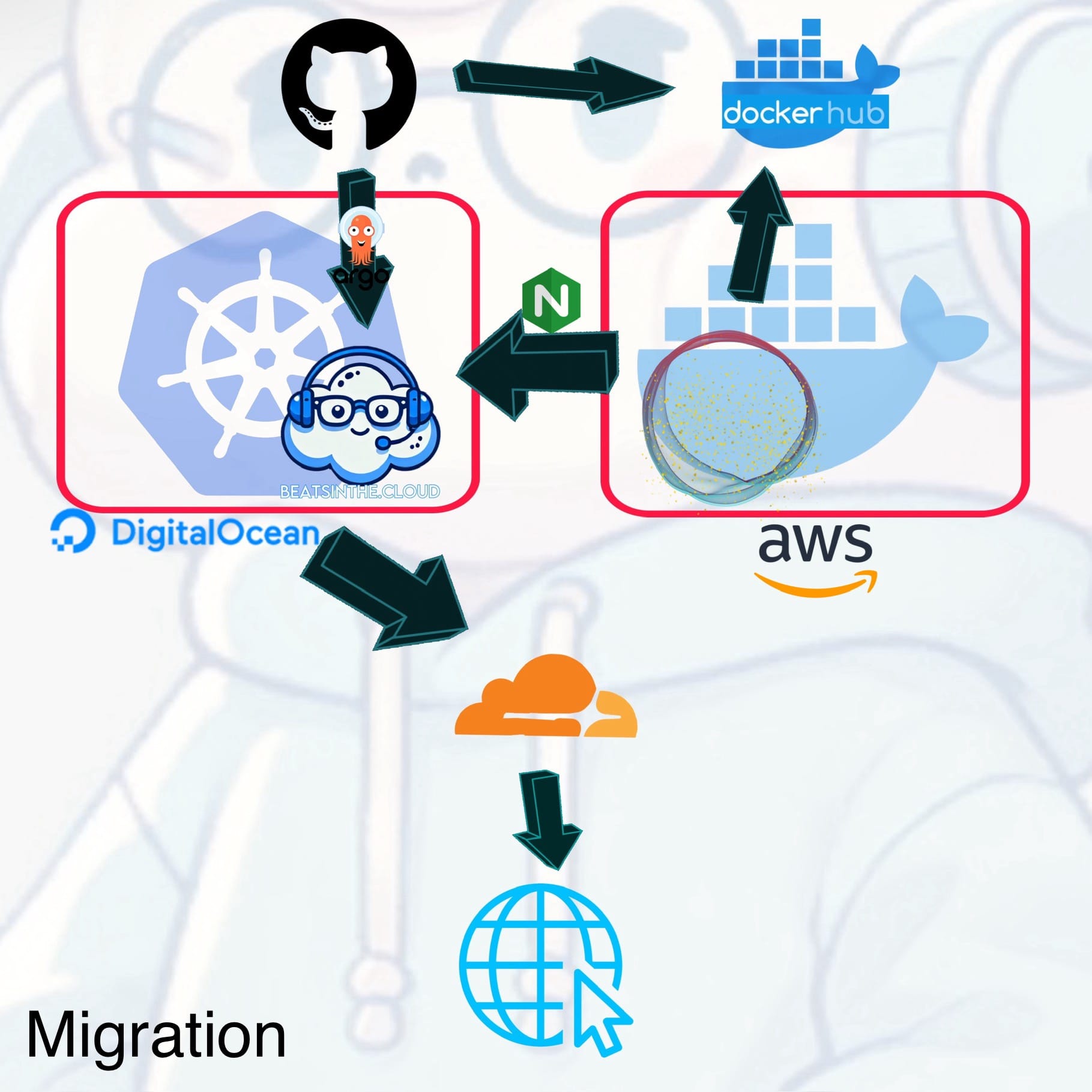
By consolidating to Hetzner, I gained more control over the infrastructure, reduced operational costs (in the nick of time), and simplified troubleshooting by having a single environment. The observability stack helped ensure a smooth migration with minimal downtime. The last setup involving reverse proxying and multi-cloud dependencies was overly complex for the current requirements. In short: it SUCKED. And it was a pain in the ass to set up. Directly integrating the Ghost blog into the K3s cluster simplified the architecture, eliminated latency issues, and made the deployment more manageable.
Since I’m still in the process of working out deploying Ghost through a 100% GitOps approach to my K3s cluster for more fine grained control over themes and controls (I’ve looked at some options, some have not worked for my use case, others look more promising), I settled on creating a custom image of my Ghost instance and its Database, sending it to my private Dockerhub repository for deployment through Argo, by keeping the deployment manifest on GitHub with referenced secrets, yet instructing Argo to ignore it on reconciliation (it is also in its own namespace), because redeployment causes the entire Ghost blog template to start from scratch, which is infuriating. But alas.
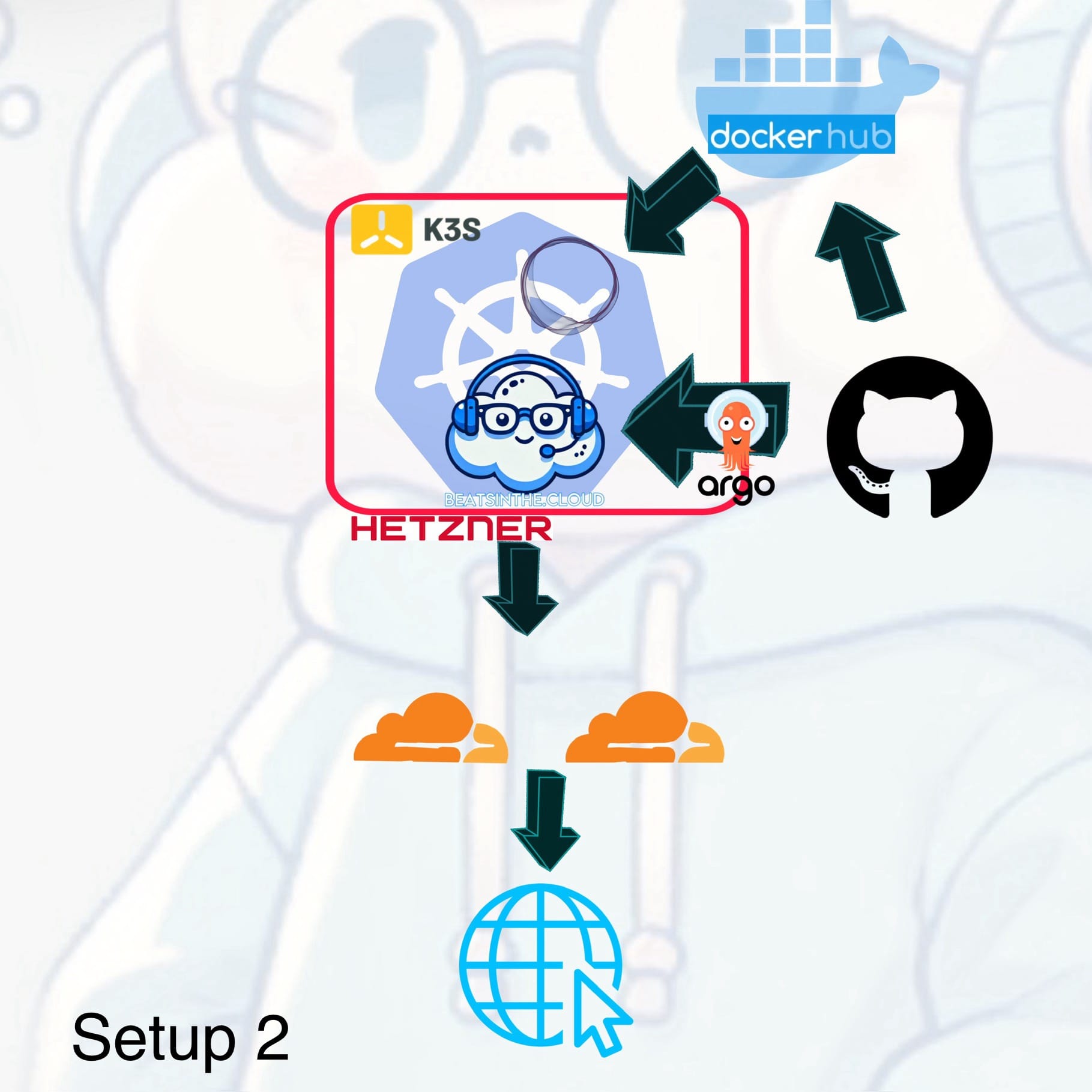
Direct integration reduced architectural complexity and improved performance by allowing traffic to flow more efficiently. Monitoring became easier since all services were running within the same environment. This stage paved the way for future security enhancements by simplifying the enforcement of security policies across the unified cluster. With the architecture streamlined, it was time to focus on security hardening to protect the deployment from potential threats.
While the previous setup was functional, it lacked proactive security measures, such as real-time monitoring for unusual activities and robust access controls.
So besides on optimizing the firewall, I wanted to focus on enhancing security by deploying Falco as an Intrusion Detection System, sending alerts to Slack for fast incident response. I also implemented 2FA for secure access to my Ghost blog admin dashboard. I already have DNS proxying activated on Cloudflare to protect against DDOS attacks. These measures ensured the environment was more secure and compliant with best practices, preparing it for production readiness.
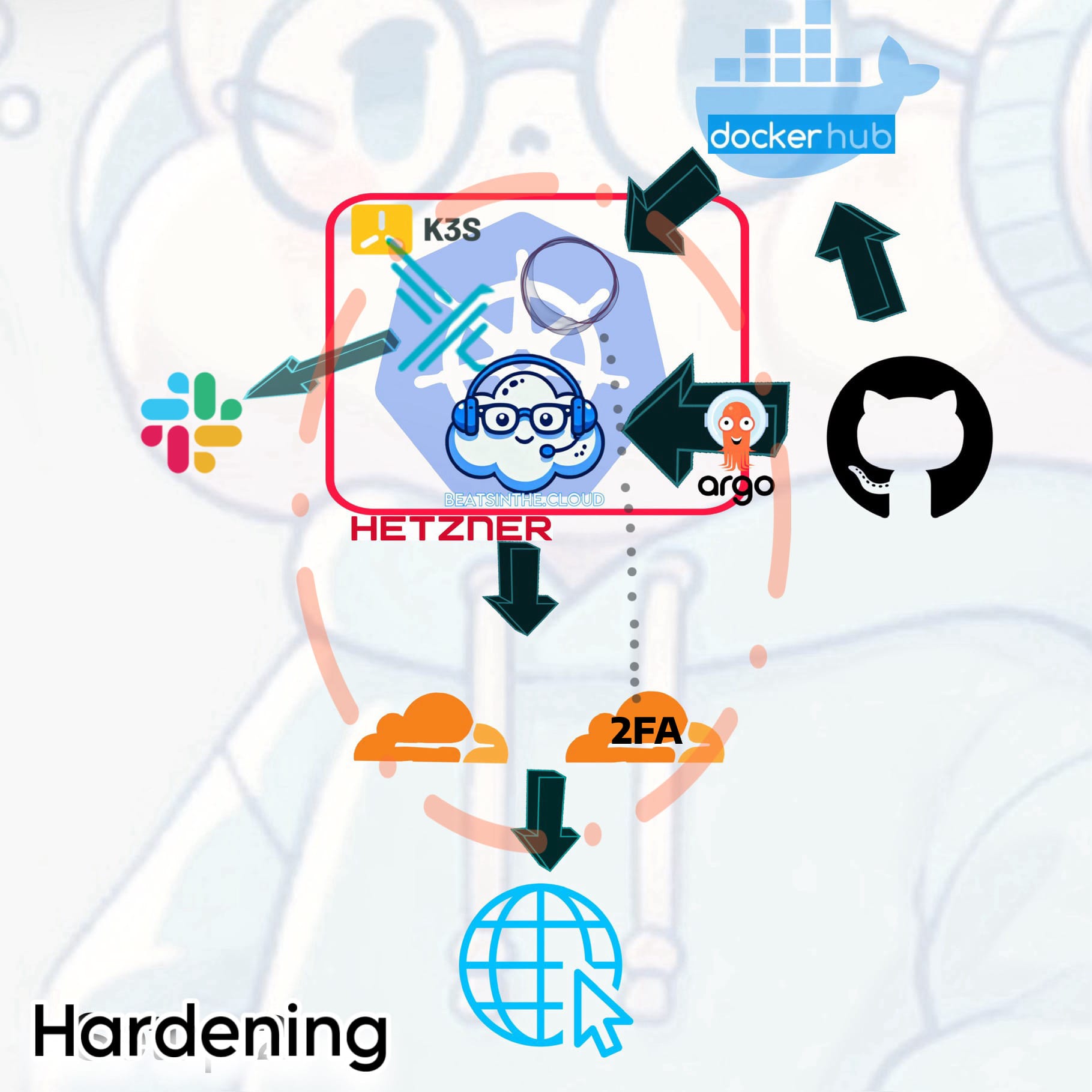
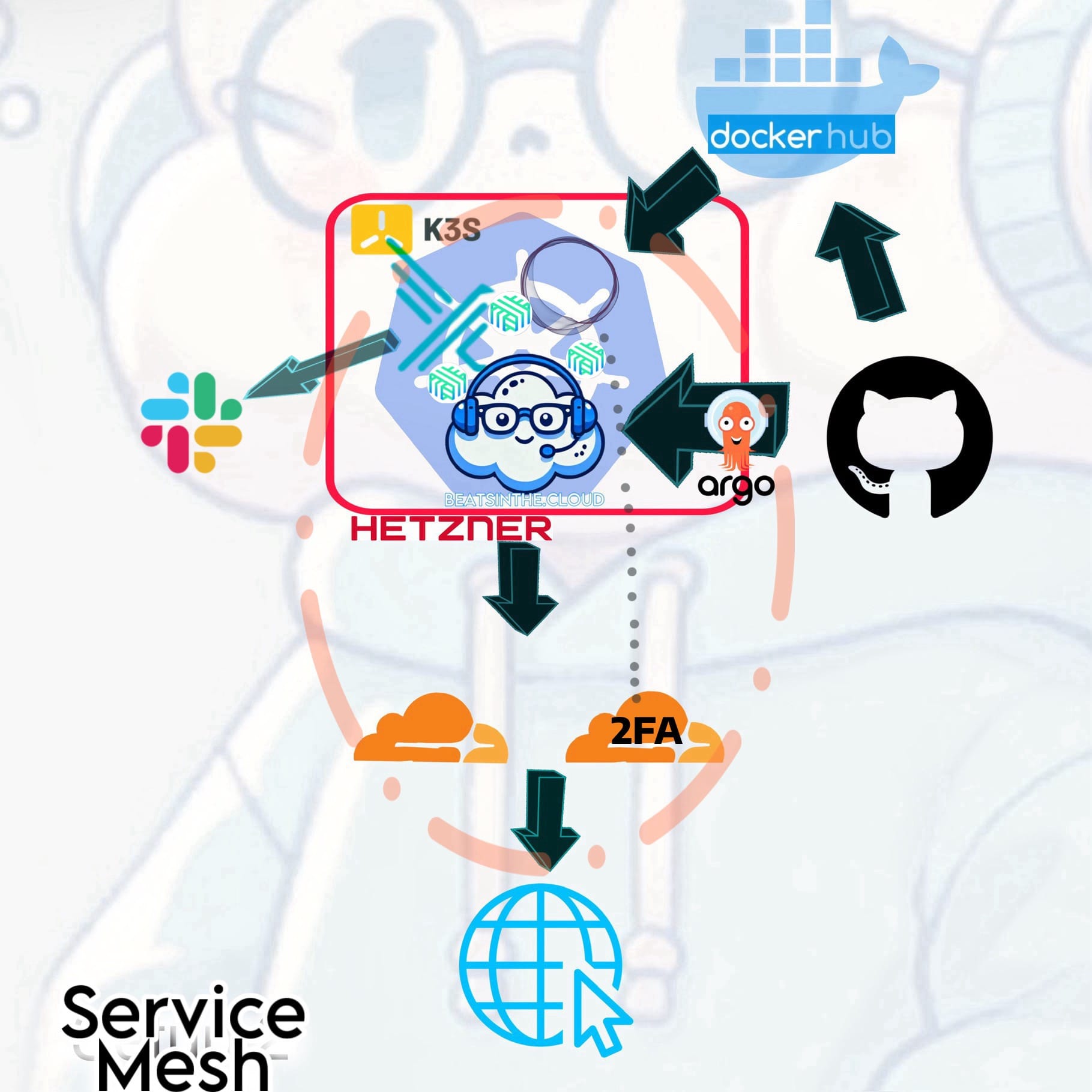
Falco provided monitoring, yet there was still a need for better control and visibility over internal traffic. I figured a service mesh would introduce more advanced features like traffic encryption, load balancing, and observability of inter-service communication, as I still had PTSD from my reverse proxy debacle, and since I intend to add further elements to the site in the near future.
At this stage, I introduced Linkerd as the service mesh to manage the communication between services more effectively within the K3s cluster. Linkerd is lightweight as hell and faster than it's service mesh peers for efficient traffic management and enforcement of security policies, providing features like network observability and load balancing between services. At first, I was heavily choosing to go with Cilium, as I was believing the online hype. But I want to make sure I have enough resources for any traffic spikes if/when horizontal scaling triggers. So I spun up a clone of my setup as a test environment and tried it and Linkerd side-by side, and compared resources usage and inter-service communication. Based on metrics and benchmarks, Linkerd outperformed it and utilized less memory and resources, and I didn't even bother trying Istio because it's just too complicated for my setup. Your mileage may vary depending on your use case.
Linkerd gave me fine-grained traffic control, enhanced network security, and improved observability at the network layer. It also enabled better load balancing and traffic routing within the cluster, complementing the existing monitoring tools (Prometheus and Grafana) by providing deeper insights into network traffic.
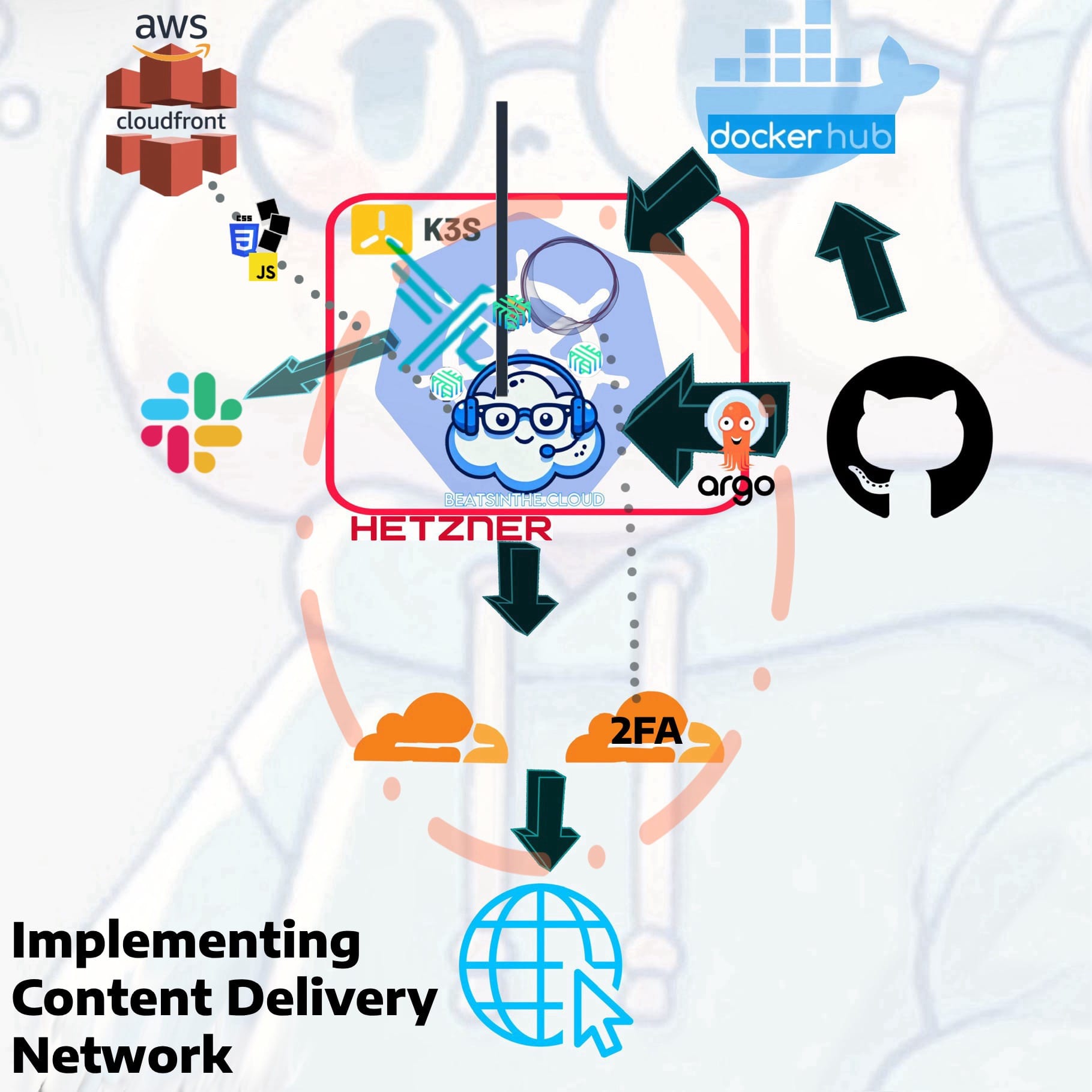
So I was feeling proud, accomplished, and saw improved performance and responsiveness in the different elements of my site. However, after being slightly shamed by Google Lighthouse, there was a need to improve performance for global users. While internal traffic was optimized, external users would benefit from a Content Delivery Network (CDN) to reduce latency and enhance the delivery of static assets.
So I went back crawling to AWS like a scummy ex for CloudFront as a CDN to serve images, JavaScript, and CSS scripts, offloading static content from the K3s cluster. This setup allowed assets to be cached closer to users, ensuring faster global loading times. Using CloudFront to cache static assets reduced the workload on the K3s cluster and improved content delivery speed for end-users. This optimization enhanced the user experience, especially for those accessing the site from different geographical locations.
So this seemingly complicated setup was at aimed at simplifying management, reducing cost, enhancing security, and optimizing performance. It took about a 6 months to plan and execute, with more to come, as it's not even it's final form. My Rocketbook and whiteboard look like Charlie Kelly working out Pepe Silvia. I was able to simultaneously address challenges, while taking my skills outside of textbooks, simulation labs and youtube video courses.
Plus I was able to solve for running out of credits and trying to stay under budget, and make the deployment more robust, secure, and user-friendly. I encourage you to sharpen your skills in cloud architecture, Kubernetes management, GitOps, network security, observability, and content delivery, progressively refining your infrastructure for a well-rounded, scalable deployment, doing the same for friends and clients along the way, learning how to build enterprise-level architecture and security at a good cost.
Next step....migrating to another (cheaper) provider, since I just found out I can get triple the power for the same cost, while creating an active failover, ALSO switching to a different remote container registry that offers more than one private repository. I love you, Dockerhub, but I don't want another monthly subscription. Since I want to add forum and e-commerce elements (y'all want stickers and shirts, or SOCKS?), this would be the best solutions as this platform scales. But, first, how do I get my VM image off of Hetzner? Hmmm.
Stay tuned.
Drop me a line on the site I refuse to call by the most edgelord letter in the alphabet.




